set
- 고유한 항목들의 정렬되지 않은 컬렉션
⇒ 중복X, 순서X.
{}, mutable - 정해진 순서가 없기 때문에 어떻게 접근해야될지 고민해 보야함
- 단순히 print()만 할 경우 순서가 항상 다르게 나올 수 있다.
set 메서드
s.add(x): 세트 s에 항목 x를 추가, 이미 x가 있다면 변화Xs.clear(): s의 모든 항목을 제거 ⇒set()출력됨s.remove(x): s에서 x 제거, x가 없으면Key errors.pop(): s에서임의의요소를 제거하고반환- 근본적으로 리스트와 작동은 비슷함, but 임의의 요소를 제거
- 출력 됐을 때 가장 첫 ( 가장 왼쪽) 의 요소가 제거
- 우리가 흔히 생각하는 무작위가 아니다
s.discard(x): s에서 항목 x를 제거 ,반환없음s.update(iterable): s에 다른iterable요소를 추가extend와 비슷함
set 집합 메서드
set1.difference(set2): set1 - set2 , 차집합, set1 에만들어 있는 항목으로 set생성 후반환set1.intersection(set2): set & set2, 교집합, 공통 항목으로 세트반환set1.issubset(set2): set1 ≤ set2 100% 채워져야된다. 좌항이 우항에 포함T/F반환set1.issuperset(set2): set1 ≥ set2, 100% 채워져야된다. 우항이 좌항에 포함T/F반환set1.union(set2): set1 || set2, 합집합, 전부 합해서 세트반환
set1 = {0,1,2,3,4}
set2 = {1,3,5,7,9}
set3 = {0,1}
print(set1.difference(set2)) #{0, 2, 4}
print(set1.intersection(set2)) #{1, 3}
print(set1.issubset(set2)) #False
print(set1.issuperset(set2)) #False
print(set1.issuperset(set3)) #True
print(set1.union(set2) # {0, 1, 2, 3, 4, 5, 7, 9})dictionary
- 고유한 항목들의 정렬되지 않은 Collection
⇒ 중복X, 순서X.{}, mutable - Json에서 데이터를 전송 시 많이 사용되는 데이터 타입 ⇒ 매우 중요
dict 메서드
D.clear(): 딕셔너리 D의 키/값 쌍을 제거D.get(k): 키 k에 연결된 값을반환, 키가 없으면None
D[k]은 get과 비슷하지만, 에러 발생함D.get(k,v): k에 연결된 값을반환, 키가 없으면 기본 값으로v반환
.get(key[,default])안내 문구를 default에 넣어서 사용 할 수도 있다.D.keys(): 딕셔너리 키를 모은 객체를 반환dict_keys(['name', 'age'])이런 식으로 출력- key의 모임
- 왜
[ ]로 묶여있지? 그럼 반복이 가능하겠네
print(person.values()) # dict_keys(['name', 'age']) for key in person.keys(): print(key, end=' ') # name ageD.values()딕셔너리 값을 모은 객체를 반환dict_values(['Alice', 25])
print(person.values()) # dict_values(['Alice', 25]) for v in person.values(): print(v, end=' ') # Alice 25D.items()dict_items([('name', 'Alice'), ('age', 25)])이런 식으로 출력
print(person.items()) # dict_items([('name', 'Alice'), ('age', 25)]) for key,value in person.items(): print(key,value) # name Alice # age 25D.pop(k)키를 제거하고 연결됐던 값을반환(없으면error나default반환)D.pop(k,v).pop(key[,default])기본 형태
print(person.pop('age')) print(person) print(person.pop('country',None))D.setdefault(k)키가 연결된값을 반환D.setdefault(k,v).setdefault(key[,default])- 키가 없다면 default와 연결한 키를 딕셔너리에
추가하고 default를 반환 (.get과의 차이)
D.update(other)other가 제공하는 키/값 쌍으로 딕셔너리를 갱신, 기존 키는 덮어 씀.update([other])키워드 인자를 사용해서 덮어쓰기도 가능
other_person = { 'name' : 'Jane', 'gender':'Female' } person.update(other_person) print(person) person.update(age=50, country='KOREA') # iterable 형태가 아니라도 항목 추가 할 수도 있다 print(person)
해시 테이블 매우중요
- 임의의 요소와 관련된 이야기
- 해시 함수를 사용하여 변환한 값을 색인(index)으로 삼아 키(key)와 데이터 (value)를 저장하는 자료구조
- ⇒ 데이터를 효율적으로 저장하고 검색하기 위해 사용
- 충돌하지 않고 빠르게 꺼내온다
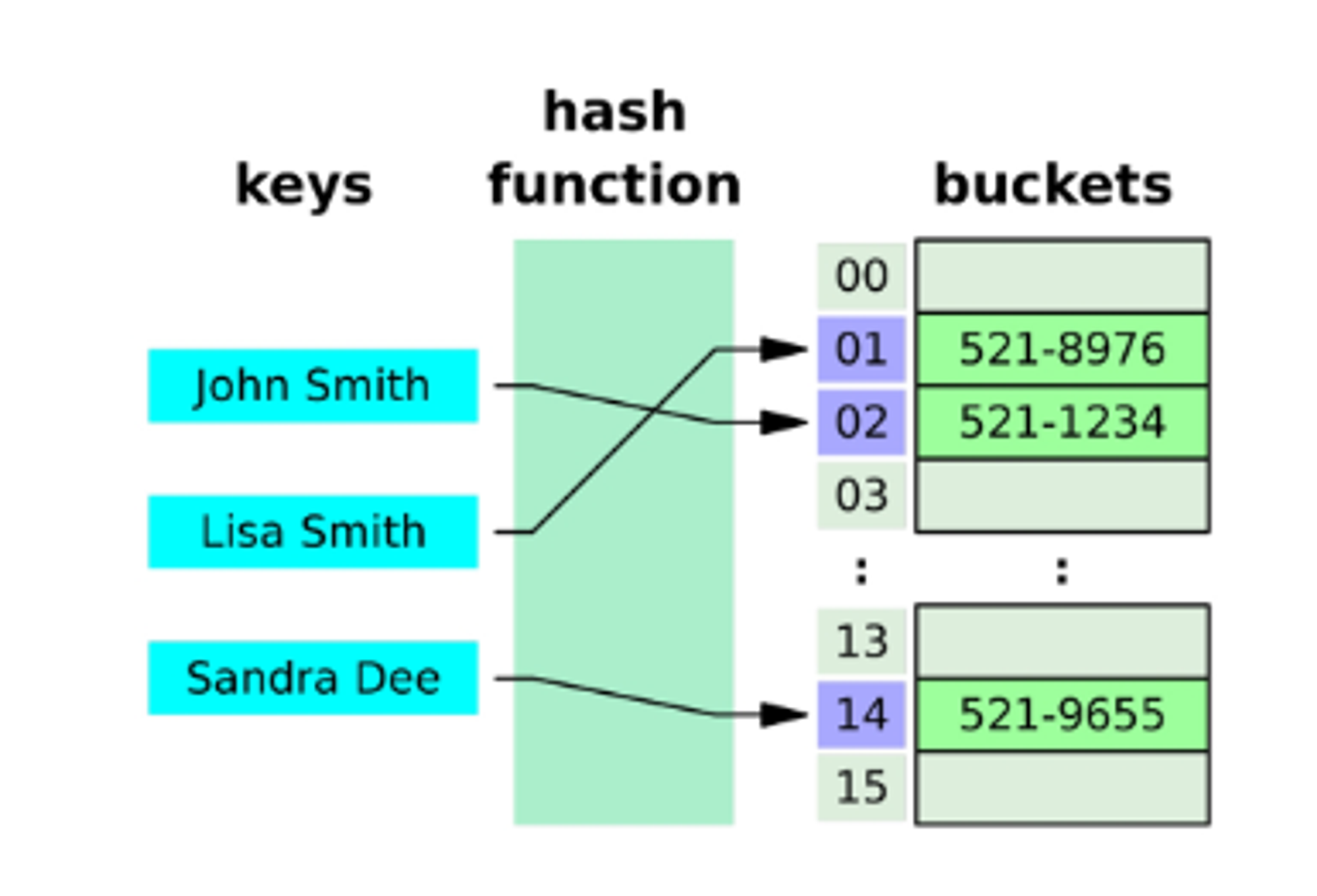
해시테이블 원리
list = [ {'john' : '521-1234'}, {'Lisa' : '521-8976'}, {'Sandra' : '521-9655'},
... 약 만개
]
dict = { 'john' : '521-1234', 'Lisa' : '521-8976', 'Sandra' : '521-9655'
...약 만개
}만약 Lisa 를 찾고 싶을 때 List 는 처음부터 하나씩 비교하면서 찾음(선형 검색) ⇒ 검색시간이 배수로 늘어난다. 하지만 dict는 순서랑 무관하게 바로 찾아버림
왜? 해시 함수 덕분
딕셔너리가 저장될 때 이 키를 해시테이블에 넣어서 어떠한 색인 값(메모리 상의 방) 얻어냄
해시 함수는 내장되있음
key가 해시 함수를 거쳐서 value를 꺼내온다. ⇒ 데이터 검색 속도가 매우 빠르다.
해시 Hash
-
임의의 크기를 가진 데이터를고정된 크기의 고유한 값으로 변환하는 과정 - 이렇게 생성된 고유한 값을 주로 해당 데이터를 식별하는데 사용될 수 있음
= 순서가 상관없다 ⇒ set, dict 자료형
- 일종의 ‘
지문’ 같은 역할 - 데이터를 고유하게 식별
- 일종의 ‘
- 파이썬에서는 해시 함수는 사용하여 데이터를 해시 값으로 변환하며, 이 해시값을 색인 값으로 쓴다. 이 떄 해시 값은 정수로 표현된다.
ex) 279007865759382685
해시 함수
- 임의의 길이의 데이터 입력 → 고정된 길이의 데이터(해시 값)를 출력
ex) 279007865759382685 - 주로 해시 테이블 자료구조(key, hash function, busket 포함되는 일련의 과정) 에 사용
⇒ 매우 빠른 데이터 검색을 위한 컴퓨터 소프트웨어에서 유용하게 사용 - 해시 함수가 어떻게 도는지는 개발자는 알 수 없음
set 요소 & dictionary의 키와 해시테이블 관계
- 파이썬에서
세트의 요소와 딕셔너리의키는 해시 테이블을 이용하여 중복되지 않는 고유한 값을 저장함⇒ 고유한 값은 부여받았다, ⇒ 하지만!! 순서는 존재 하지 않는다,
⇒ 왜냐?? 해시 함수를 거쳐야지 알 수 있기 때문,
또한 순서는 중요 하지 않다. 고정된 위치를 받기 때문
- 세트 내의 각 요소는 해시 함수를 통해 해시 값으로 변환되고, 이 해시 값을 기반으로 해시 테이블에 저장됨
- 마찬가지로 딕셔너리의 키도 고유해야만 함
키를 해시 함수를 통해 해시 값으로 변환 ⇒ 해시 테이블에 저장
⇒ 따라서 딕셔너리의 키는 매우 빠른 탐색 속도를 제공하는 동시에 중복된 값을 허용 X
set pop메서드 예시 - 정수
순서가 없는 정수는 굳이 추가적인 처리가 필요 없다.
⇒ 정수 값 자체가 곧 해시 값
⇒ 해시테이블에 나열된 순서로 나옴(단순한 방 번호)
⇒ 순서는 없다 단지 정수는 자기 방 번호가 있을 뿐이다.
⇒ 해시테이블에서 색인 순서로 나열된 순서 대로 나온다
⇒ pop이란 해시테이블의 먼저 있는 순서로 뺀다.
⇒ 정수’만’ 있다면, 무조건 1 부터 pop될 것이다.
⇒ 하지만 문자열이 섞인다면 모른다. ⇒ 임의의 수가 나온다고 표현
print(hash(1)) # 1
print(hash(1)) # 1
print(hash('a')) # (랜덤)279007865759382685
print(hash('a')) # 279007865759382685
매번 실행 할 때마다 문자열의 방번호는 바뀐다.해시 함수를 거친 이후의 값을 확인할 수 있을까?
hash()라는 내장함수 사용
- 파이썬에서 해시 함수의 동작 방식은 객체의
타입에 따라 달라짐 - 정수와 문자열은 서로 다른 타입
⇒ 이들의 해시 값을 계산하는 방식도 다름
임의(가변)라는 개념에서 무작위다
⇒ 랜덤 이라는 개념 X
pop은 해시 함수가 적용 된 후 (해시테이블 위에서) 배치상 첫번째를 뽑아오는것
해시 함수가 매번 배치를 변경시킴
By ‘arbitary’ the docs don’t mean ‘random’ : 파이썬 공식 문서 에서의 내용
⇒ 해시 테이블에 나타나는 순서대로 반환하는 것
hashable
hash() 함수의 인자로 전달해서 결과를 반환 받을 수 있는 객체를hashable이라 함
대부분 immutable 한 것은 hash가 가능,
⇒ hash가능 = 불변하다도 아님
⇒ 하지만 무조건은 아니다. 일반화 절대 금지
단, tuple의 경우 불변형임
⇒ 해시 불가능한 객체를 참조할 때는 tuple 자체도 해시 불가능해지는 경우가 있다.
print(hash((1,2,3))) #가능
print(hash((1,2,[3,4]))) #typeError 발생hash와 불변성 간의 관계
- 해시 테이블의 키는 불변해야 함
- 객체가 생성된 후 그 값을 변경할 수 없어야 함
- 불변 객체는 해시 값이 변하지 않음 ⇒ 동일한 값에 대해 일관된 해시 값을 유지 가능
빠른 검색과 조회가 가장 중요함
해시테이블은 무결성을 위해 존재한다.
가변형 객체가 hashable 하지 않은 이유
- 값이 변경될 수 있기 때문에 동일한 객체에 대한 해시 값이 변경될 가능성 있음
⇒ 해시 테이블의 무결성 유지 불가
- 가변형 객체가 변경 ⇒ 해시 값 변경
⇒ 같은 객체에 대한 서로 다른 해시 값 반환될 수 있음
⇒ 해시 값의 일관성 유지 불가
print(hash([1,2,3])) # TypeError: unhashable type: 'list' my_set = {[1,2,3],1,2,3,4,5} # TypeError: unhashable type: 'list' my_dict = {{3,2}:'a'} # TypeError: unhashable type: 'set'set 타입도 가변성을 가지기 때문에 딕셔너리의 키로 들어가지 못함
hashable 객체가 필요한 이유
- 해시 테이블 기반 자료 구조 사용
- set와 dict의 키
- 중복 값 방지
- 빠른 검색과 조회
- 불변성을 통한 일관된 해시 값
- 안정성과 예측 가능성 유지
추가로 배운 것
변수초기화 할때
min = max = list[0] 이렇게 해도 됨해야 되는 것
- pop() 이 리스트 세트 딕셔너리 별로 차이가 있다
- 해시 테이블 정리 : 완
궁금한 것
딕셔너리의 값은 변경가능하지 않나?
메소드로 뺴고 넣고하는건 별개의 프로세스인가?
'TIl' 카테고리의 다른 글
| OOP 2 (1) | 2024.01.25 |
|---|---|
| OOP1 (1) | 2024.01.24 |
| 데이터 구조1 (1) | 2024.01.22 |
| Weekly 일, 파이썬 복습 (1) | 2024.01.21 |
| 파이썬 1주차 Weekly 토 (0) | 2024.01.20 |

