SQL
데이터베이스 : 체계적인 데이터 모음
데이터 : 저장이나 처리에 효율적인 형태로 변환된 정보
데이터 사용량은 갈수록 폭발적으로 증가되어가고 있음
⇒ 데이터 센터의 성장
⇒ 데이터를 저장하고 잘 관리하여 활용할 수 있는 기술이 중요해짐
기존의 데이터 저장 방식 : 파일(File), 스프레드 시트(Spreadsheet)
- 파일을 이용한 데이터 관리
- 어디에서나 쉽게 사용 가능
- 데이터를 구조적으로 관리하기 어려움
- 스프레드 시트를 이용한 데이터 관리
- 테이블의 열과 행을 사용해 데이터를 구조적으로 관리 가능
- 한계 :
- 크기 : 일반적으로 100만 행까지만 가능
- 보안 : 단순한 접근 권한 기능만 제공
- 정확성 : 데이터 값이 하나 바뀌었을 때 이것을 전부 다 업데이트해야됨 ⇒ 추가문제 발생가능성 높음
데이터베이스 역할
데이터를 저장(구조적 저장)하고 조작(CRUD)
Relational Database 관계형 데이터베이스
데이터간에 관계가 있는 데이터 항목들의 모음
- 테이블, 행, 열의 정보를 구조화하는 방식
- 서로 관련된 데이터 포인터를 저장하고 이에 대한 액세스를 제공
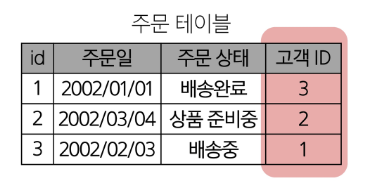
관계 : 여러 테이블 간의 (논리적) 연결
관계로 할 수 있는 것
- 이 관계로 인해 두 테이블을 사용하여 데이터를 다양한 형식으로 조회할 수 있음
- 특정 날짜에 구매한 모든 고객 조회
- 지난 달에 배송일이 지연된 고객 조회 등
관련 키워드
- Table ( = Relation)
- 데이터를 기록하는 곳
- Field ( = Column, Attribute )
- 각 필드에는 고유한 데이터 형식(타입)이 지정됨
- Record ( = Row, Tuple )
- 각 레코드에는 구체적인 데이터 값이 저장됨
- Database ( = Schema )
- 테이블의 집합
- Primary Key ( 기본 키, PK)
- 각 레코드의 고유한 값, 데이터 무결성
- 관계형 데이터베이스에서 레코드의 식별자로 활용

- Foreign Key ( 외래 키, FK)
- 테이블의 필드 중 다른 테이블의 레코드를 식별할 수 있는 키
- 다른 테이블의 기본 키를 참조 , 참조 무결성 가짐
- 각 레코드에서 서로 테이블 간의 관계를 만드는 데 사용
DBMS. Database Management System
데이터베이스를 관리하는 소프트웨어 프로그램
- 데이터 저장 및 관리를 용이하게 하는 시스템
- 데이터베이스와 사용자 간의 인터페이스 역할
- 사용자가 데이터 구성, 업데이트, 모니터링, 백업, 복구 등을 할 수 있도록 도움
RDBMS. Relational DBMS
관계형 DB를 관리하는 소프트웨어 프로그램
종류
- SQLite
- MySql
- Oracle …
데이터베이스 정리
- Table은 데이터가 기록되는 곳
- Table에는 행에서 고유하게 식별 가능한 기본 키 라는 속성이 있으며, 외래 키를 사용하여 각 행에서 서로 다른 테이블 간의 관계를 만들 수 있음
- 데이터는 기본 키 또는 외래 키를 통해 결합(join)될 수 있는 여러 테이블에 걸쳐 구조화 됨
SQL. Structure Query Language
DB에 정보를 저장하고 처리하기 위한 프로그래밍 언어
=⇒ 테이블의 형태로 구조화(Structure)된 관계형 데이터베이스에게 요청을 질의(요청)(Query)
SQL Syntax
SELECT column_name FROM table_name;
- SQL 키워드는 대소문자를 구분하지 않음
- but 대문자로 작성하는 것을 권장 (명시적 구분)
- 각 SQL Statements의 끝에는 세미클론(’;’)이 필요
- 세미클론은 각 SQL Statements을 구분하는 방법(명령어의 마침표)
SQL Statements
SQL을 구성하는 가장 기본적인 코드 블록
SELECT column_name FROM table_name;
- 해당 코드를 SELECT Statement라 부름
- 이 Statement는 SELECT, FROM 2개의 keyword로 구성 됨
수행 목적에 따른 SQL Statements 4가지 유형
- DDL - 데이터 정의
- DQL - 데이터 검색
- DML - 데이터 조작
- DCL - 데이터 제어
| 유형 | 역할 | SQL 키워드 |
| DDL (Data Definition Language) |
데이터의 기본 구조 및 형식 변경 | CREATE DROP ALTER |
| DQL (Data Query Language) |
데이터 검색 | SELECT |
| DML (Data Manipulation Language) |
데이터 조작 (추가, 수정, 삭제) | INSERT UPDATE DELETE |
| DCL (Data Control Language) |
데이터 및 작업에 대한 사용자 권한 제어 | COMMIT ROLLBACK GRANT REVOKE |
Query
- “데이터베이스로부터 정보를 요청” 하는 것
- 일반적으로 SQL로 작성하는 코드를 쿼리문(SQL문) 이라 함
SQL 표준
- SQL은 미국 국립 표준 협회(ANSI)와 국제 표준화 기구(ISO)에 의해 표준이 채택됨
- 모든 RDBMS에서 SQL 표준을 지원
- 다만 각 RDBMS마다 독자적인 기능에 따라 표준을 벗어나느 문법이 존재함
Query data
SELECT statement : 테이블에서 데이터를 조회
SELECT -- SELECT 키워드 이후 데이터를 선택하려는 필드르 하나 이상 지정
select_list
FROM -- FROM 키워드 이후 데이터를 선택하려는 테이블의 이름을 지정
table_name;
- 모든 필드 데이터 조회 : SELECT * FROM employees;
- AS = 출력 할 때 보이는 이름 바꾸기 : SELECT LastName, FirstName AS '이름' FROM employees;
- 필드의 값을 나눈값으로 출력 : select_list/ 숫자
⇒ 테이블의 데이터를 조회 및 반환
’*’ (asterisk)를 사용하여 모든 필드 선택
ORDER BY statement : 조회 결과의 레코드를 정렬
- FROM 뒤에 위치
- 하나 이상의 컬림을 기준으로 결과를 오름차순(ASC, 기본 값), 내림차순(DESC)으로 정렬
- 모든 데이터 오름차순 조회 SELECT * FROM table_name ORDER BY FirstName;
- 모든 데이터 내림차순 조회 SELECT * FROM table_name ORDER BY FirstName DESC;
- 내림차순 → 오름차순 SELECT Country, City FROM customers ORDER BY Country DESC City ASC;
- 출력 값에 따른 order SELECT Name, Milliseconds / 60000 AS ' 재생 시간(분)' FROM tracks ORDER BY Milliseconds DESC
정렬에서 NULL은 오름차순 정렬 시 먼저 출력 됨
SELECT statement 실행 순서
FROM → SELECT → ORDER BY
테이블에서(FROM) 조회하여(SELECT) 정렬한다(ORDER BY)
Filtering data
관련 키워드
Clause
- DISTINCT
- WHERE
- LIMIT : 조회하는 레코드 수를 제한, ORDER BY 다음에 나온다
- 하나 또는 두 개의 인자를 사용 (0 또는 양의 정수)
- row_count는 조회하는 최대 레코드 수를 지정
- LIMIT [offset,] row_count;
- 예시 LIMIT 2, 5; ⇒ 3~7까지 나옴 LIMIT 5 OFFSET 2
Operator
- Comparison (비교) : =, ≥, IS, LIKE, IN, BETWEEN, … AND
- BETWEEN
- IN : 값이 특정 목록 안에 있는지 확인
- LIKE : 값이 특정 패턴에 일치하는지 확인 (Wildcards와 함께 사용)
- Wildcard Characters
- ‘%’ : 0개 이상의 문자열과 일치하는지 확인
- ‘_’ : 단일 문자와 일치하는지 확인
- Wildcard Characters
- Logical (논리) : AND(&&), OR(||), NOT(!)
DISTINCT statement : 조회 결과에서 중복된 레코드를 제거
SELECT DISTINCT Country FROM customers ORDER BY Country;
- SELECT 키워드 바로 뒤에 작성해야 함
- SELECT DISTINCT 키워드 다음에 고유한 값을 선택하려는 하나 이상의 필드를 지정
WHERE statement : 조회 시 특정 검색 조건을 지정
SELECT select_list FROm table_name WHERE search_condition;
- FROM clause 뒤에 위치
- search_condition 은 비교연산자 및 논리 연산자(AND, OR, NOT 등)를 사용하는 구문이 사용됨
GROUP BY clause
레코드를 그룹회하여 요약본 생성 (’집계 함수’와 함께 사용)
Aggregation Functions 집계 함수
값에 대한 계산을 수행하고 단일한 값을 반환하는 함수
SUM, AVG, MAX, MIN, COUNT
GROUP BY syntax
- FROM 및 WHERE 절 뒤에 배치
- GROUP BY 절 뒤에 그룹화 할 필드 목록을 작성
SELECT
c1,c2,...cn, aggregate_function(ci)
FROM
table_name
GROUP BY
c1, c2, ... cn;
GROUP BY Country : Country 필드를 그룹화
COUNT(*) : COUNT 함수가 각 그룹에 대한 집계된 값을 계산
예시)
tracks 테이블에서 Composer 필드를 그룹화하여 각 그룹에 대한 Bytes의 평균 값을 내림차순 조회
SELECT Composer, AVG(Bytes) FROM tracks GROUP BY Composer ORDER BY AVG(Bytes) DESC;
예시 2)
tracks 테이블에서 Composer 필드를 그룹화하여 각 그룹에 대한 MIlliseconds의 평균 값이 10 미만인 데이터 조회
SELECT Composer, AVG(Milliseconds/ 60000) FROM tracks GROUP BY Composer HAVING AVG(Milliseconds/ 60000) < 10;
HAVING clause
- 집계 항목에 대한 세부 조건을 지정
- 주로 GROUP BY와 함꼐 사용되며 GROUP BY가 없다면 WHERE 처럼 동작
SELECT statement 실행 순서
FROM ⇒ WHERE ⇒ GROUP BY ⇒ HAVING ⇒ SELECT ⇒ ORDER BY ⇒ LIMIT
Managing Tables. DDL
Create a table statement: 테이블 생성
- 각 필드에 적용할 데이터 타입 작성
- 테이블 및 필드에 대한 제약조건(constraints)작성
주의해야할 것 : , 로 이어지는건 컬럼명 끼리만 함, data_type 과 constraints(제약 조건) 간에는 ,가 없음
CREATE TABLE table_name (
column_1 data_type constraints,
column_2 data_type constraints,
column_3 data_type constraints,
);
CREATE TABLE examples(
ExamId INTEGER PRIMARY KEY AUTOINCREMENT,
LastName VARCHAR(50) NOT NULL,
FirstName VARCHAR(50) NOT NULL,
PRAGMA
- 테이블 schema(구조) 확인
PRAGMA table_info('examples');
cid :
- Column ID를 의미하며 각 컬럼의 고유한 식별자를 나타내는 정수 값
- 직접 사용하지 않으며 PRAGMA 명령과 같은 메타데이터 조회에서 출력 값으로 활용됨
SQLite 데이터 타입
- NULL : 아무런 값도 포함하지 않음을 나타냄
- INTEGER : 정수
- REAL : 부동 소수점
- TEXT : 문자열
- BLOB : 이미지, 동영상, 문서 등의 바이너리 데이터
Constraints 제약조건
테이블의 필드에 적용되는 규칙 또는 제한 사항
⇒ 데이터의 무결성을 유지하고 데이터베이스의 일관성을 보장
대표 제약 조건 3가지
- PRIMARY KEY
- 해당 필드를 기본 키로 지정
- INTEGER 타입에만 적용되며 INT, BIGINT 등과 같은 다른 정수 유형은 적용되지 않음
- NOT NULL
- 해당 필드에 NULL 값을 허용하지 않도록 지정
- FOREIGN KEY
- 다른 테이블과의 외래 키 관계를 정의
AUTOINCREMENT keyword
자동으로 고유한 정수 값을 생성하고 할당하는 필드 속성
- 필드의 자동 증가를 나타내는 특수한 키워드
- 주로 primary key 필드에 적용
- INTEGER PRIMARY KEY AUTOINCREMENT가 작성된 필드는 항상 새로운 레코드에 대해 이전 최대 값보다 큰 값을 할당
- 삭제된 값은 무시되며 재사용할 수 없게 됨
Modifying table fields
ALTER TABLE statement
테이블 및 필드 조작
| 명령어 | 역할 |
| ALTER TABLE ADD COLUMN | 필드 추가 |
| ALTER TABLE RENAME COLUMN | 필드 이름 변경 |
| ALTER TABLE RENAME TO | 테이블 이름 변경 |
1. ADD COLUMN syntax
- ADD COLUMN 키워드 이후 추가하고자 하는 새 필드 이름과 데이터 타입 및 제약 조건 작성
- ALTER TABEL table_name ADD COLUMN column_definition;
- 단, 추가하고자 하는 필드에 NOT NULL 제약조건이 있을 경우 NULL이 아닌 기본 값 설정 필요
- ex)
ADD COLUMN COUNTRY VARCHAR(100) NOT NULL DEFAULT 'default value';
ex 2) SQlite는 단일 문을 사용하여 한번에 여러 필드를 추가할 수 없음
ADD COLUMN Age INTEGER NOT NULL DEFAULT 0;
ADD COLUMN Address VARCHAR(100) NOT NULL DEFAULT 'default value';
2. RENAME COLUMN systax
- ALTER TABLE table_name RENAME COLUMN current_name TO new_name
- RENAME COLUMN 키워드 뒤에 이름을 바꾸려는 필드의 이름을 지정하고 TO 키워드 뒤에 새 이름을 지정
ALTER TABLE examples RENAME COLUMN address TO PostCode;
3. RENAME TO systax
- ALTER TABLE table_name RENAME TO new_table_name
- RENAME TO 키워드 뒤에 새로운 테이블 이름 지정
ALTER TABLE examples RENAME TO new_examples;
DELETE a Table
DROP TABLE statement 테이블 삭제
DROP TABLE table_name;
Modifying Data
DML (Data Manipulation Language) 데이터 조작
INSERT, UPDATE, DELETE
INSERT statement 테이블 레코드 삽입
- column 과 value는 1대1 대응관계를 가짐
INSERT INTO table_name ( c1, c2, ...)
VALUES (v1, v2, ...);
-- ex)
INSERT INTO articles (title, content, createdAt)
VALUES ('hello','world','2000-01-01'),
('hello','world','2000-01-01'), -- 여러개일때는 이렇게 넣어야함
('hello','world',DATE()); -- DATE 함수를 사용해서 추가 입력
UPDATE statement 테이블 레코드 수정
- where 절을 작성하지 않으면 모든 레코드를 수정
UPDATE table_name
SET column_name = expression,
[WHERE condition];
-- ex)
UPDATE articles
SET title = 'update Title'
content = 'update content'
WHERE id = 1;
DELETE statement 테이블 레코드 삭제
DELETE FROM table_name
[WHERE condition];
-- ex)
DELETE FROM articles
WHERE id in (
SELECT id FROM articles
ORDER BY createdAt
LIMIT 2
);
- where 절을 작성하지 않으면 모든 레코드를 삭제
update와 delete 에서 where은 생략 가능함.
⇒ 하지만 생략 시 모든 테이블에 적용되기때문에 조심해야됨
Multi table queries
관계 : 여러 테이블 간의 (논리적) 연결
Join이 필요한 순간
- 테이블을 분리하면 데이터 관리는 용이해질 수 있으나 출력시에는 문제가 있음
- 테이블 한 개 만을 출력할 수 밖에 없어 다른 테이블과 결합하여 출력하는 것이 필요해짐
⇒ ‘JOIN’
Joining tables
JOIN clause 둘 이상의 테이블에서 데이터를 검색하는 방법
종류
1. INNER JOIN 교집합
둘 테이블에서 값이 일치하는 레코드에 대해서만 결과를 반환
- FROM 절 이후 메인 테이블 지정(table_a)
- INNER JOIN 절 이후 메인 테이블과 조인할 테이블을 지정(table_b)
- ON 키워드 이후 조인 조건을 작성
- 조인 조건 : table_a 와 table_b 간의 레코드를 일치시키는 규칙을 지정
SELECT select_list
FROM table_a
INNER JOIN table_b
ON table_b.fk = table_a.pk;
-- ex)
SELECT * FROM articles
INNER JOIN users
ON users.id = articles.userId;
-- ex 2)
SELECT articles.title, users.name FROM articles
INNER JOIN users
ON users.id = articles.userId
WHERE users.id = 1;
2. LEFT JOIN
오른쪽 테이블의 일치하는 레코드와 함께 왼쪽 테이블의 모든 레코드 반환
- 왼쪽 테이블의 모든 레코드를 표기
- 오른쪽 테이블과 매칭되는 레코드가 없으면 NULL을 표시
SELECT select_list
FROM table_a
LEFT JOIN table_b
ON table_b.fk = table_a.pk;
-- ex) 게시글을 작성한 이력이 없는 회원 정보 조회
SELECT * FROM users
LEFT JOIN articles
ON articles.userId = users.id
WHERE articles.userId IS NULL;
참고
타입 선호도 (Type Affinity)
컬럼에 데이터 타입이 명시적으로 지정되지 않았거나 지원하지 않을 때 SQLite가 자동으로 데이터 타입을 추론하는 것
목적
- 유연한 데이터 타입 지원
- 데이터 타입을 명시적으로 지정하지 않고도 데이터를 저장하고 조회할 수 있음
- 칼럼에 저장되는 값의 특성을 기반으로 데이터 타입을 유추
- 간편한 데이터 처리
- INTEGER Type Affinity를 가진 열에 문자열 데이터를 저장해도 SQLite는 자동으로 숫자로 변환하여 처리
- SQL 호환성
- 다른 데이터베이스 시스템과 호환성을 유지
반드시 NOT NULL 제약을 사용해야 할까?
답은 “NO”
- 하지만 데이터베이스를 사용하는 프로그램에 따라 NULL을 저장할 필요가 없는 경우가 많으므로 대부분 NOT NULL을 정의
- “값이 없다.” 라는 표현을 테이블에 기록하는 것은 “0” 이나 “빈 문자열” 등을 사용하는 것으로 대체하는 것을 권장
SQLite의 날짜와 시간
- SQLite에는 날짜 및/또는 시간을 저장하기 위한 별도 데이터 타입이 없음
- 대신 날짜 및 시간에 대한 함수를 사용해 표기 형식에 따라 TEXT, REAL, INTEGER 값으로 저장
- https://www.sqlite.org/datatype3.html