Tree
- 비선형 구조
- 원소들 간에 1:n 관계를 가지는 자료구조
- 원소들 간의 계층관계를 가지는 계층형 자로구조
- 상위 원소에서 하위 요소로 내려가면서 확장되는 트리(나무)모양의 구조
정의
- 한 개 이상의 노드로 이루어진 유한 집합이며 다음 조건을 만족한다.
- 노드 중 최상위 노드를 루트(root)라 한다.
- 나머지 노드들은 n(≥0)개의 분리 집합 T1,….,TN으로 분리될 수 있다.
- 이들 T1 ~ TN은 각 각 하나의 트리가 되며(재귀적 정의) 루트의 부트리(
subtree)라고 한다.
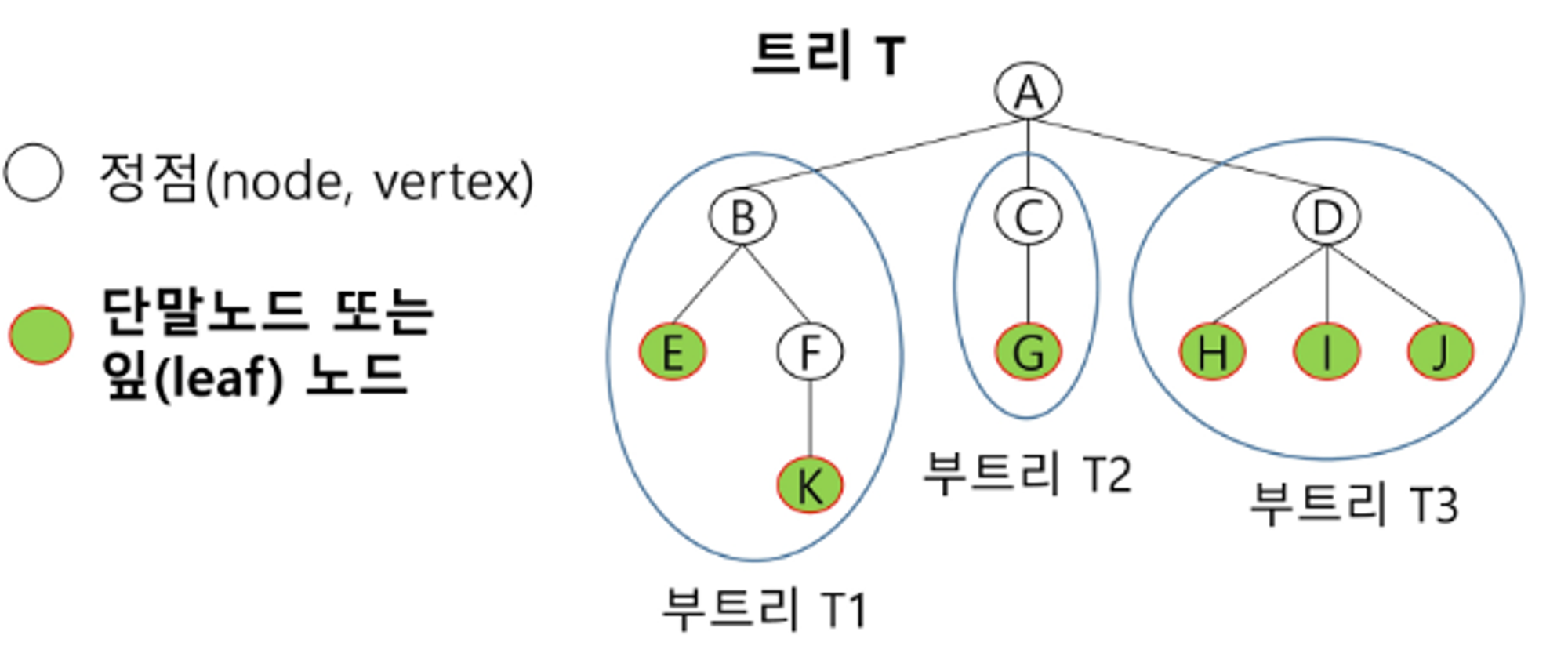
용어
- 노드(node) - 트리의 원소
- 트리 T의 노드 - A,B,C,D,E,F,G,H,I,J,K
- 간선(edge) : 노드를 연결하는 선, 부모 노드와 자식 노드를 연결
- 루트노드(root node) : 트리의 시작 노드
- 트리 T의 루트 노드 : A
- 형제 노드 : 같은 부모 노드의 자식 노드들
- B, C, D는 형제 노드
- 조상 노드 - 간선을 따라 루트 노드까지 이르는 경로에 있는 모든 노드들
- K의 조상 노드 : F,B,A
- 서브 트리 : 부모 노드와 연결된 간선을 끊었을 때 생성되는 트리
⇒ 일부만 떼어 낸 것
- 자손 노드 : 서브 트리에 있는 하위 레벨의 노드들
- B의 자손 노드 : E,F,K
- 차수
- 노드의 차수 : 노드에 연결된 자식 노드의 수 (기본 1:N 관계기 때문)
- B의 차수 = 2, C의 차수 = 1
- 트리의 차수 : 트리에 있는 노드의 차수 중에서 가장 큰 값
- 트리 T의 차수 = 3
- 단말 노드(리프 노드) : 차수가 0인 노드, 자식 노드가 없는 노드
- 노드의 차수 : 노드에 연결된 자식 노드의 수 (기본 1:N 관계기 때문)
- 높이 (= 레벨, 상대적인 개념, 0~1레벨에서 시작됨)
- 노드의 높이 : 루트에서 노드에 이르는 간선의 수, 노드의 레벨
- B의 높이 = 1, F의 높이= 2
- 트리의 높이 : 트리에 있는 노드의 높이 중에서 가장 큰 값, 최대 레벨
- 트리 T의 높이 = 3
- 노드의 높이 : 루트에서 노드에 이르는 간선의 수, 노드의 레벨
이진 트리
모든 노드들이 2개의 서브트리를 갖는 특별한 형태의 트리
각 노드가 자식 노드를 최대한 2개(0~2) 까지만 가질 수 있는 트리 (중요)
- 왼쪽 자식 노드(left child node)
- 오른쪽 자식 노드(right ~)
주의 해야 될 것
- 무조건 작은 값이 왼쪽이 들어간다 ( X )
- 모든 이진 트리는 자식노드를 가진다.( X )
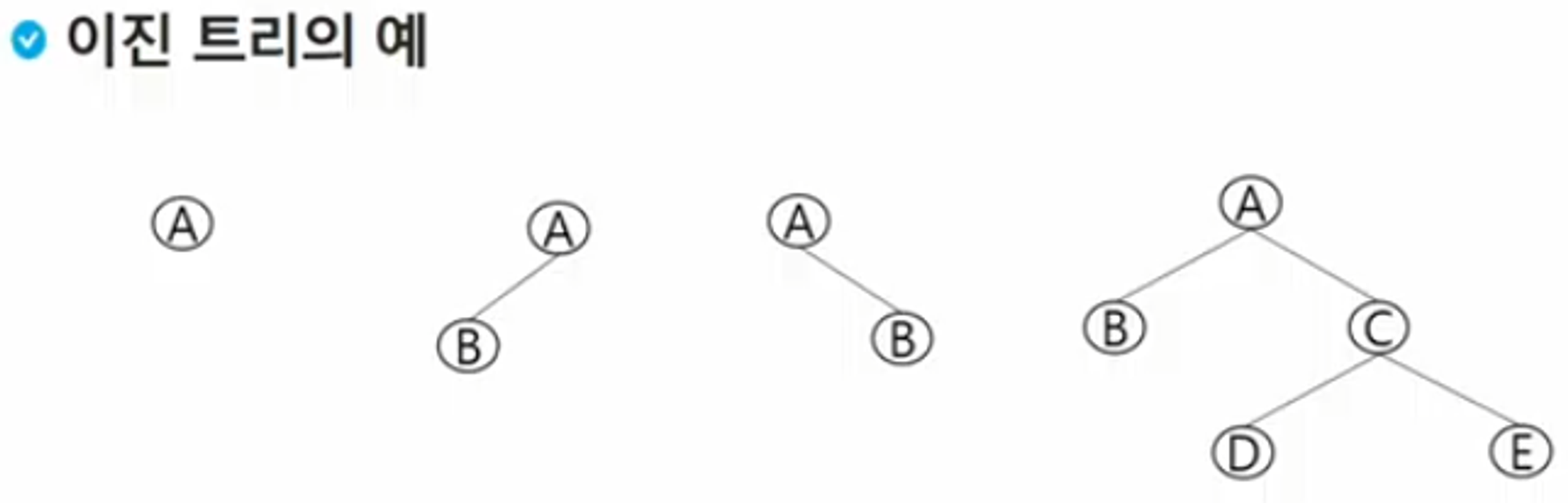
이진 트리 특성
- 레벨
i에서의 노드의 최대 개수 2개 (레벨의 시작에 따라서 다르다. - 높이가 h인 이진 트리가 가질 수 있는 노드의
- 최소 개수 $h+1$ 개 (= 레벨 0의 노드 최소 개수 1개
(A)) - 최대 개수 : $2^{h+1}-1$개
- 최소 개수 $h+1$ 개 (= 레벨 0의 노드 최소 개수 1개
포화 이진 트리 Full Binary
- 모든 레벨에 노드가 포화상태로 차 있는 이진 트리
- 높이가 h일 때, 최대의 노드 개수인 $2^{h+1}-1$의 노드를 가진 이진 트리
- 높이 3일 때 $2^{3+1}-1$ = 15개
- 루트를 1번으로 하여 $2^{h+1}-1$까지 정해진 위치에 대한 노드 번호를 가진다.
완전 이진 트리 Complete Binary
높이가 h이고 노드의 수가 n개 일 때 (단 $2^{h}$≤ $2^{h+1}$), 포화 이진 트리의 노드 번호부터 n번까지 빈 자리가 없는 이진 트리
예) 노드가 10개인 완전 이진 트리
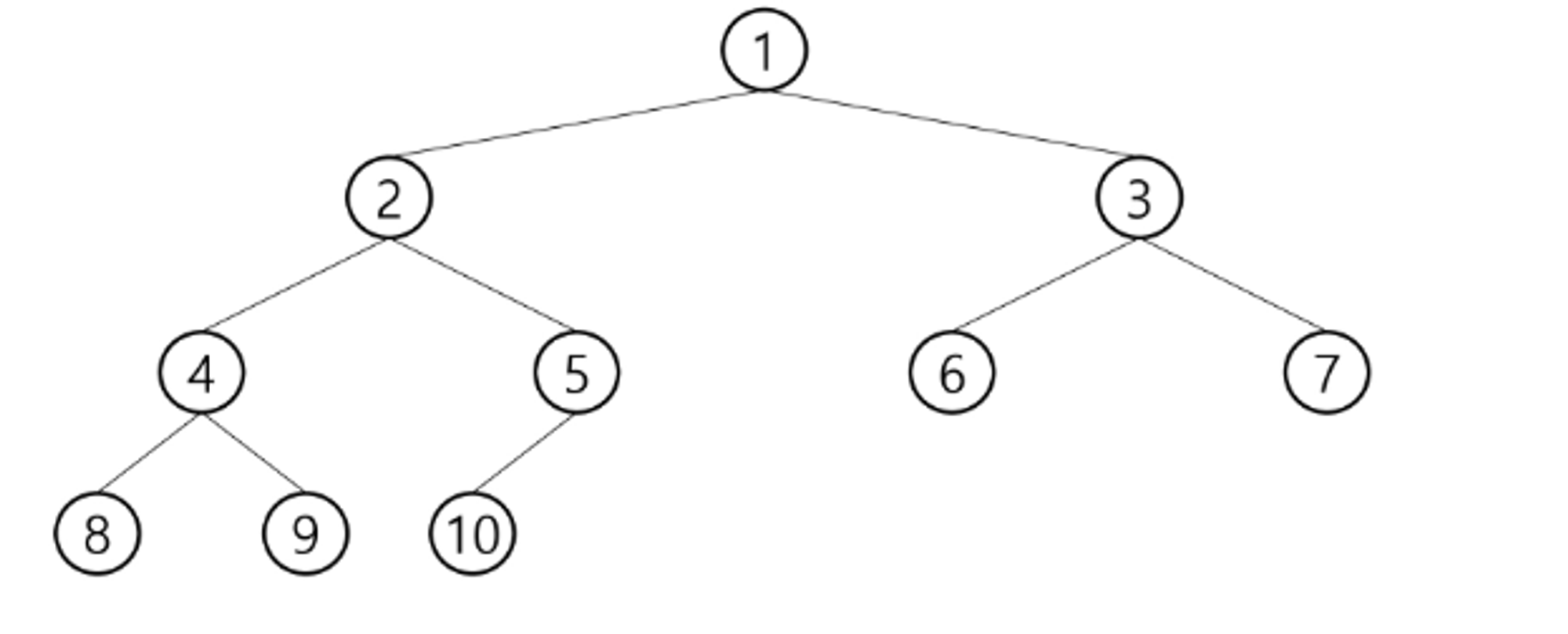
트리표현하는 방법
- 완전 이진 트리 → 1차원으로 저장 : 배열의 인덱스를 이용하는 방법
- 2차원 배열 이용하는 방법
편향 이진 트리 Shewed
트리로서의 역할을 못한다 ⇒ 좋지 않은 트리 (= 이렇게 만들지 않기 위한 알고리즘(AOL)도 존재한다)
높이 h에 대한 최소 개수의 노드를 가지면서 한쪽 방향의 자식 노드만을 가진 이진 트리,
- 왼쪽 편향
- 오른쪽 편향
순회 traversal
트리의 각 노드를 중복되지 않게 전부 방문(visit) 하는 것을 말하는데 트리는 비 선형 구조이기 때문에 선형구조에서와 같이 선후 연결 관계를 알 수 없다.
⇒ 특별한 방법 필요하다.
순회란? 트리의 노드들을 체계적으로 방문하는 것, 또한 거슬러 올라가지 않는 것
3가지 기본적인 순회 방법
전위 순회 preorder
- 수행 방법
- 1) 현재 노드 n을 방문하여 처리한다. → V
- 2) 현재 노드 n의 왼쪽 서브트리로 이동한다 → L
- 3) 현재 노드 n의 오른쪽 서브트리로 이동한다. → R
- 전위 순회 알고리즘
def preorder_traverse(T): # 전위순회
if T: # T is not None, 부모가 존재하네
visit(T) # print(T.item)
preorder_traverse(T.left)
preorder_traverse(T.left)중위 순회 inorder
- 수행 방법
- 1) 현재 노드 n의 왼쪽 서브트리로 이동한다 → L
- 2) 현재 노드 n을 방문하여 처리한다. → V
- 3) 현재 노드 n의 오른쪽 서브트리로 이동한다. → R
def preorder_traverse(T): # 중위순회
if T: # T is not None
preorder_traverse(T.left)
visit(T) # print(T.item)
preorder_traverse(T.left)후위 순회 postorder
- 수행 방법
- 1) 현재 노드 n의 왼쪽 서브트리로 이동한다 → L
- 2) 현재 노드 n의 오른쪽 서브트리로 이동한다. → R
- 3) 현재 노드 n을 방문하여 처리한다. → V
def preorder_traverse(T): # 후위순회
if T: # T is not None
preorder_traverse(T.left)
preorder_traverse(T.left)
visit(T) # print(T.item)이진 트리의 순회
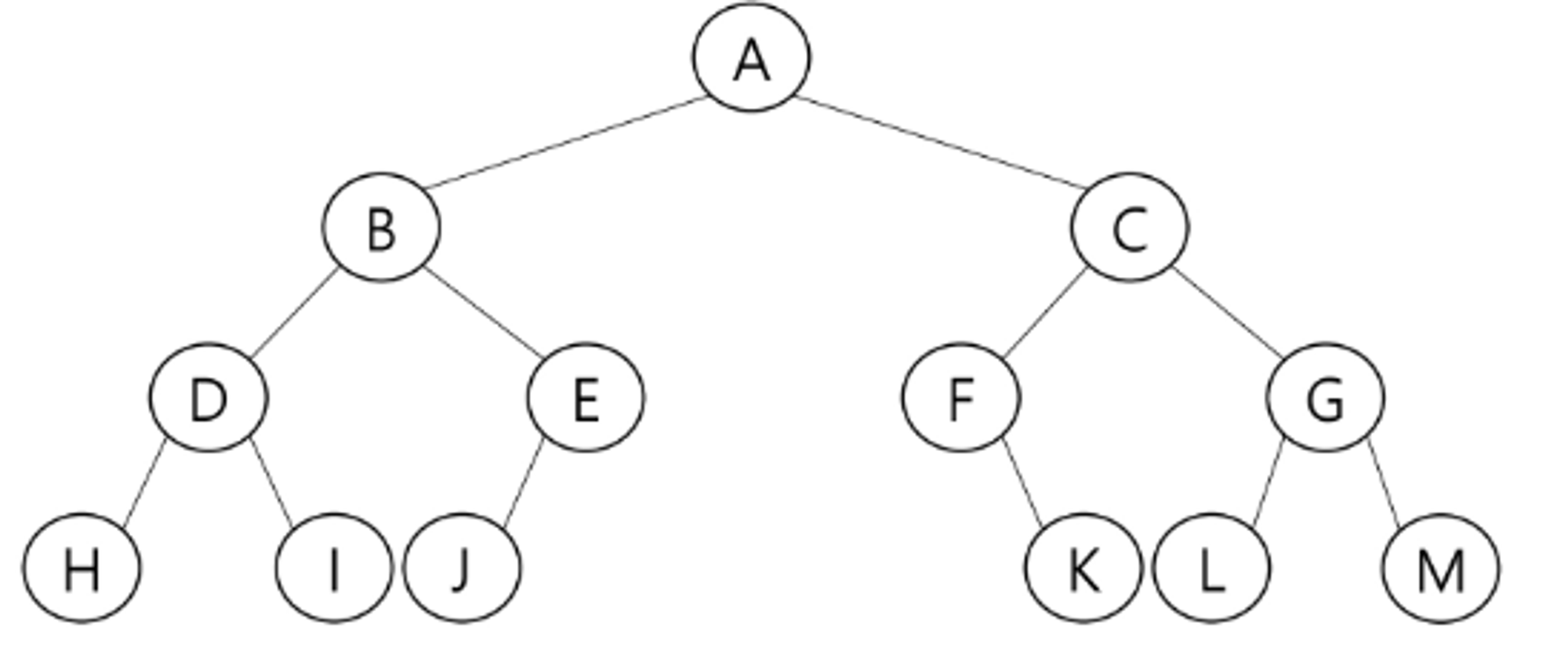
전위 순회 : A B D H I E J C F K G L M
중위 순회 : H D I B J E A F K C L G M
후위 순회 : H I D J E B K F L M G C A
이진 트리의 표현
배열을 이용한 이진 트리의 표현 (= 완전 이진 트리일 때 사용)
- 이진트리에 각 노드 번호를 다음과 같이 부여
- 루트의 번호를
대체로1로 함 - 레벨 n에 있는 노드에 대해서 왼쪽부터 오른쪽으로 $2^n$ 부터 $2^{n+1} -1$ 까지 번호를차례로부여
연습문제
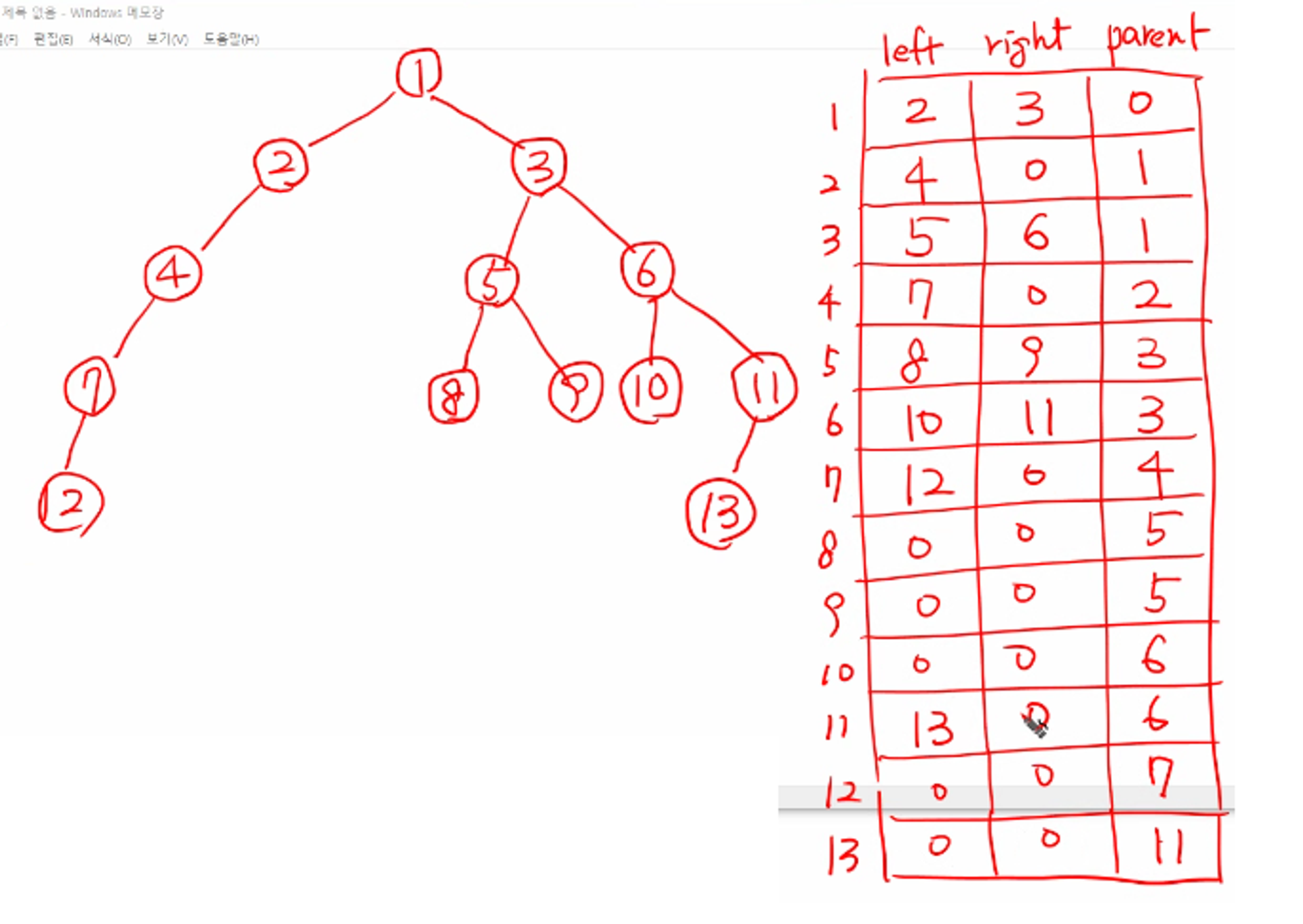
정점의 개수가 13
1 2 1 3 2 4 3 5 3 6 4 7 5 8 5 9 6 10 6 11 7 12 11 13
완전 이진트리가 아닐 때 푸는 방법
인접행렬 = 자신의 자리가 있는 인접리스트
보충 1
tree도 그래프의 일종
⇒ 표현하는 방법을 알아야 된다.
리스트처럼 인접리스트, 인접행렬 쓸 수 있다.
이진트리 : 자식노드가 최대 2개인 트리 == 차수가 2인 트리(고급진 표현)
이진트리 ⇒ 모양을 저장할 수 있는 방법이 많음
이진 트리를 저장하는 방법
- 배열 활용 : 이진 트리 중에서 포화이진트리의 경우
트리를 저장할 때 표현해야하는 정보 : 부모-자식간 관계정보 < = >
인덱스 //2 = 부모 인덱스
인덱스 * 2 = 자식 인덱스
- 행렬을 사용하는 방법
부모: 1 1 2 3 4
자식: 2 4 3 _ _
트리보다 큰 개념이 그래프
트리 < 그래프
즉, 순회하는 방법(전위,중위,후위순회) 전부 DFS
⇒ 트리는 재귀적인 형태를 가진다. ‘이들 T1,…TN은 각각 하나의 트리가 되며
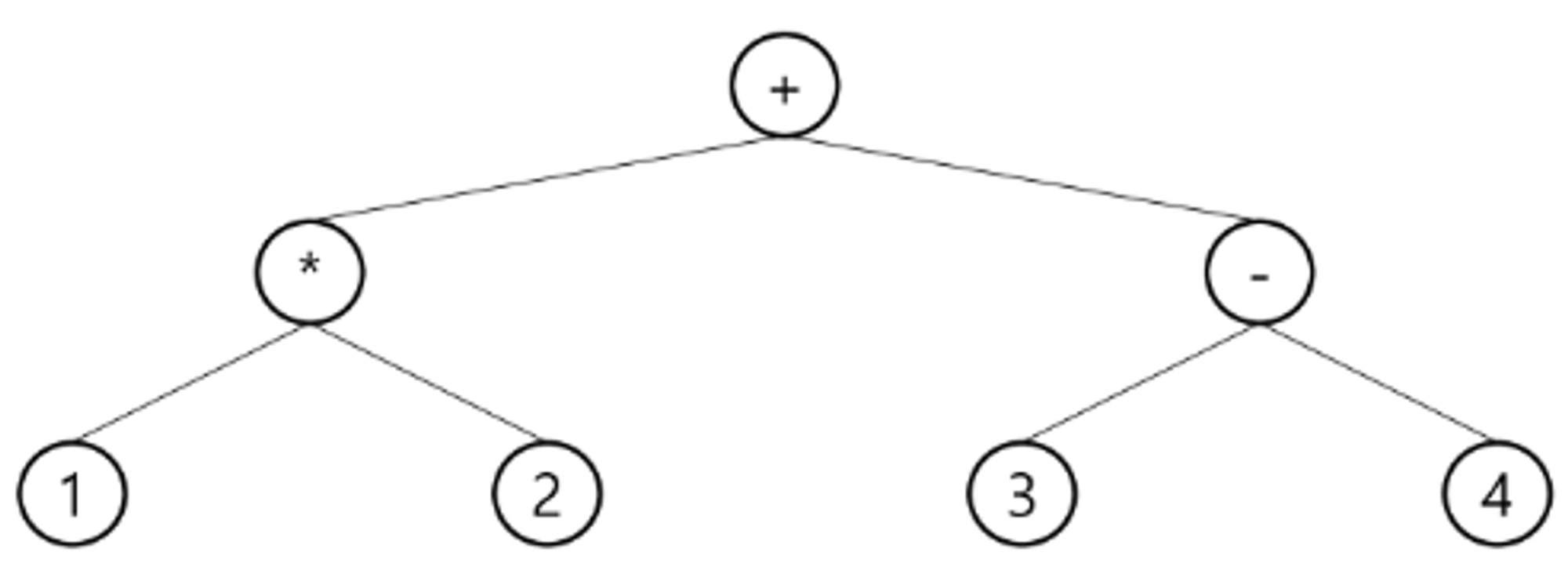
수식 트리
수식을 표현하는 이진 트리
수식 이진트리(Expression Binary Tree)라고 부르기도 함
연산자 : 루트 노드 or 가지 노드
피 연산자 : 잎 노드 (리프 노드)
후위 순회를 씀으로 해결할수 있다.
이진 탐색 트리 BST
- 탐색작업을 효율적으로 하기 위한 자료구조
- 모든 원소는 서로 다른 유일한 키를 갖는다. ( 선형 자료형의 이진 탐색이랑 차이점)
- key ( 왼쪽 서브트리) < key(루트 노드) < key(오른쪽 서브트리)
- 왼쪽 서브 트리 와 오른쪽 서브 트리도 이진 탐색 트리다.
- 중위 순회하면 오른차순으로 정렬된 값을 얻을 수 있음
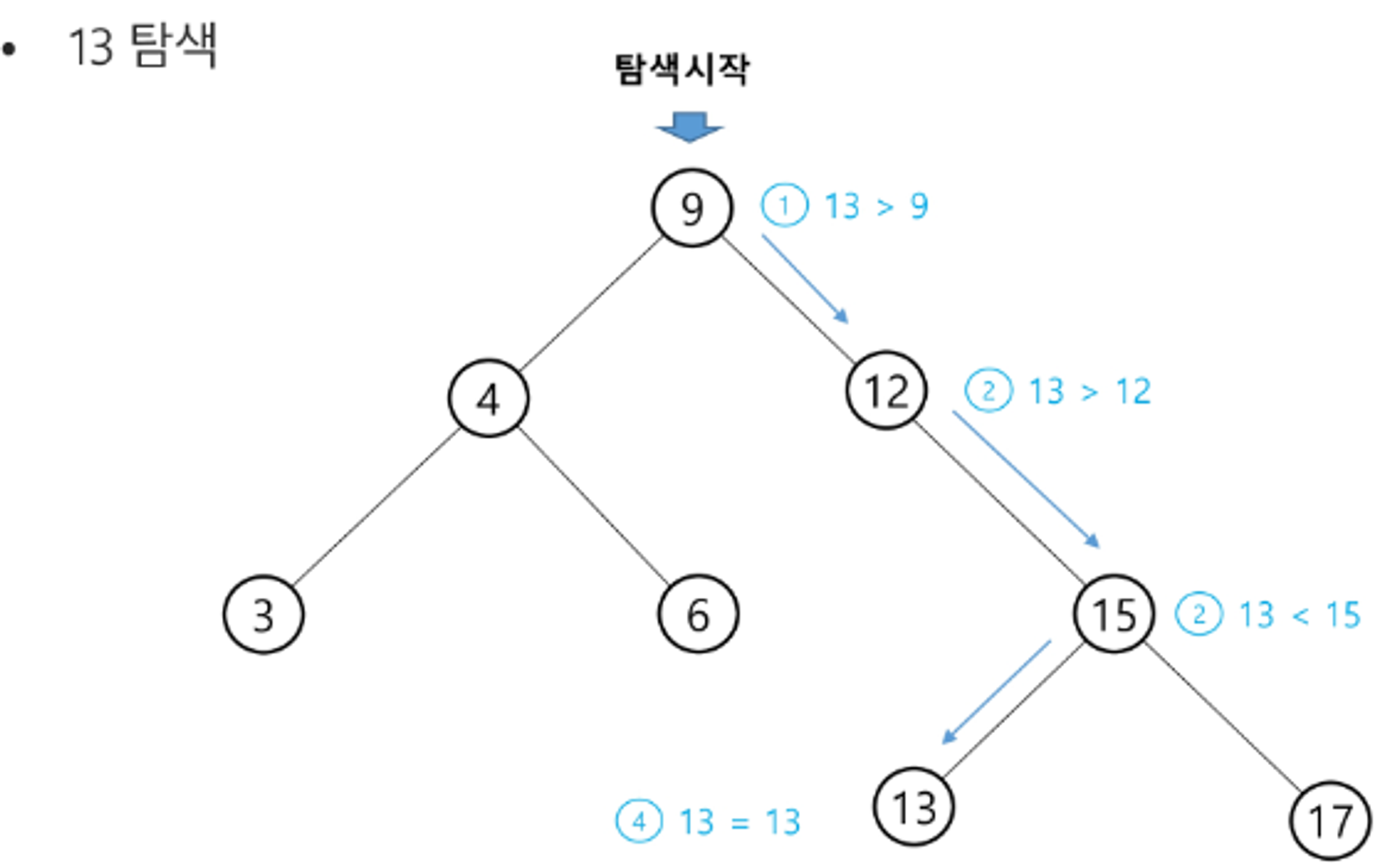
이진 탐색 트리 - 탐색 연산
- 루트에서 시작한다.
- 탐색할 키 값 x를 루트 노드의 키 값과 비교한다.
- 키 값 = 루트 노드의 키 값 : 원하는 원소를 찾았다 ⇒ 탐색연산 성공
- 키 값 < 루트 노드의 키 값 : 루트노드의 왼쪽 서브트리 ⇒ 탐색연산 수행
- 키 값 > 루트 노드의 키 값 : 루트노드의 오른쪽 서브트리 ⇒ 탐색연산 수행
⇒ 서브트리에 대해서 순환적으로 탐색 연산을 반복
이진 탐색 트리 -삽입 연산
- 탐색 연산 수행
- 삽입할 원소와 같은 원소가 트리에 있으면 삽입 할 수 없다. ⇒ 같은 원소가 트리에 있는지 탐색
- 탐색에서 탐색 실패가 결정되는 위치가 삽입 위치가 된다.
- 탐색 실패한 위치에 원소를 삽입한다.
- 5를 삽입하는 예

성능
- 탐색, 삽입, 삭제 시간은
트리의 높이만큼 시간이 걸린다.- O(h),h : BST의 깊이(height)
- 평균의 경우
- 이진 트리가 균형적으로 생성되어 있는 경우
- O(log n)
- 최악의 경우
- 한쪽으로 치우친 경사 이진트리의 경우
- O(n)
- 순차탐색과 시간복잡도가 같다.
- 검색 알고리즘의 비교
- $O(n)$:
- 배열에서의 순차검색
- 정렬된 배열에서의 순차검색
- 이진 탐색트리의 최악의 경우
- $O(logN)$
- 정렬된 배열에서의 이진탐색, 대신 고정 배열 크기와 삽입, 삭제 시 추가연산 필요함
- 이진 탐색트리에서의 평균
- 완전 이진 트리 (최악의 경우를 삭제할 수 있다)
- 균형트리 (최악의 경우를 삭제할 수 있다),
⇒ 새로운 원소를 삽입할 때 삽입 시간 줄임
- $O(n)$
- 해쉬 검색 (추가 저장 공간이 필요)
- $O(n)$:
힙 heap
완전 이진 트리에 있는 노드 중에서 키 값이 가장 큰 노드나 키 값이 가장 작은 노드를 찾기 위해서 만든 자료구조
자식 간의 키 값의 크기 차이는 순서대로가 아니다.
⇒ 부모와 자식간의 관계만 중요
- 최대 힙(max heap)
- 키 값이 가장 큰 노드를 찾기 위한 완전 이진 트리
- 부모노드의 키값 > 자식 노드의 키값
- 루트 노드 : 키 값이 가장 큰 노드
- 최소 힙 min
- 키 값이 가장 작은 노드를 찾기 위한 완전 이진 트리
- 부모 노드의 키 값 < 자식노드의 키 값
- 루트 노드 : 키 값이 가장 작은 노드
- 20000/24
힙이 아닌 트리
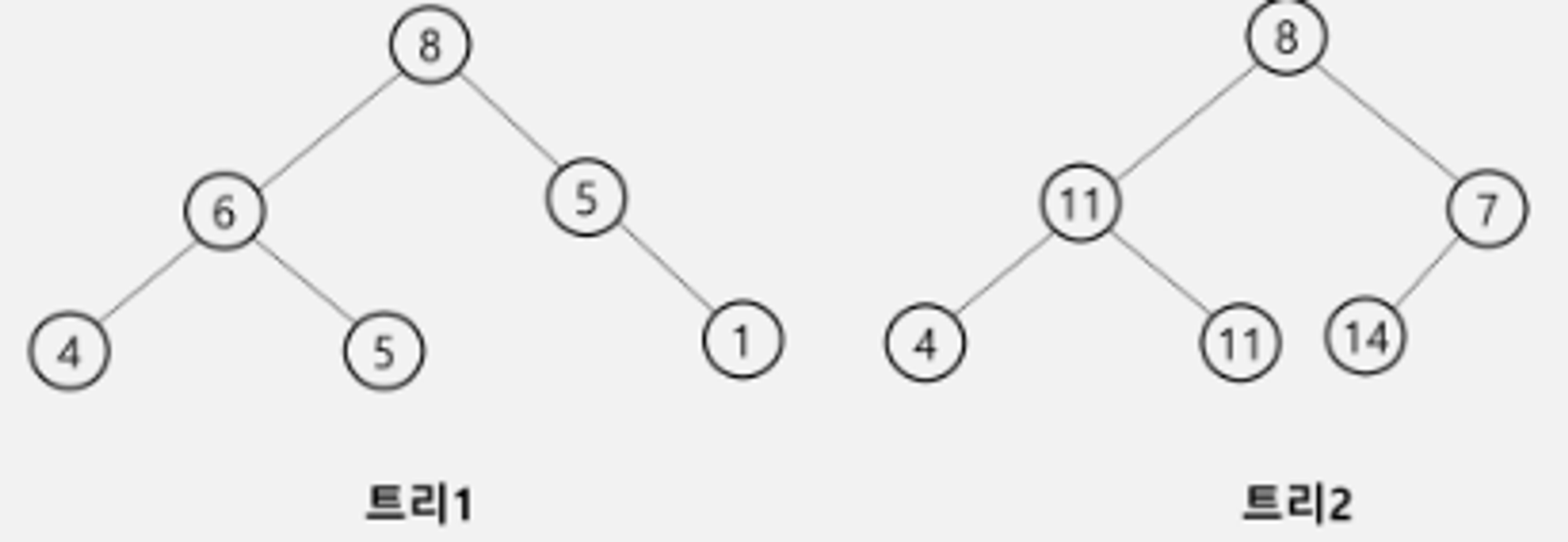
힙 연산 삽입
힙 연산 삭제
- 힙에서는 루트 노드의 원소만을 삭제 할 수 있다.
- 최대 힙의 경우 : key가 가장 큰 값
- 최소 힙의 경우 : key가 가장 작은 값
- 루트 노드의 원소를 삭제하여 반환한다.
- 힙의 종류에 따라 최대값 또는 최소값을 구할 수 있다.
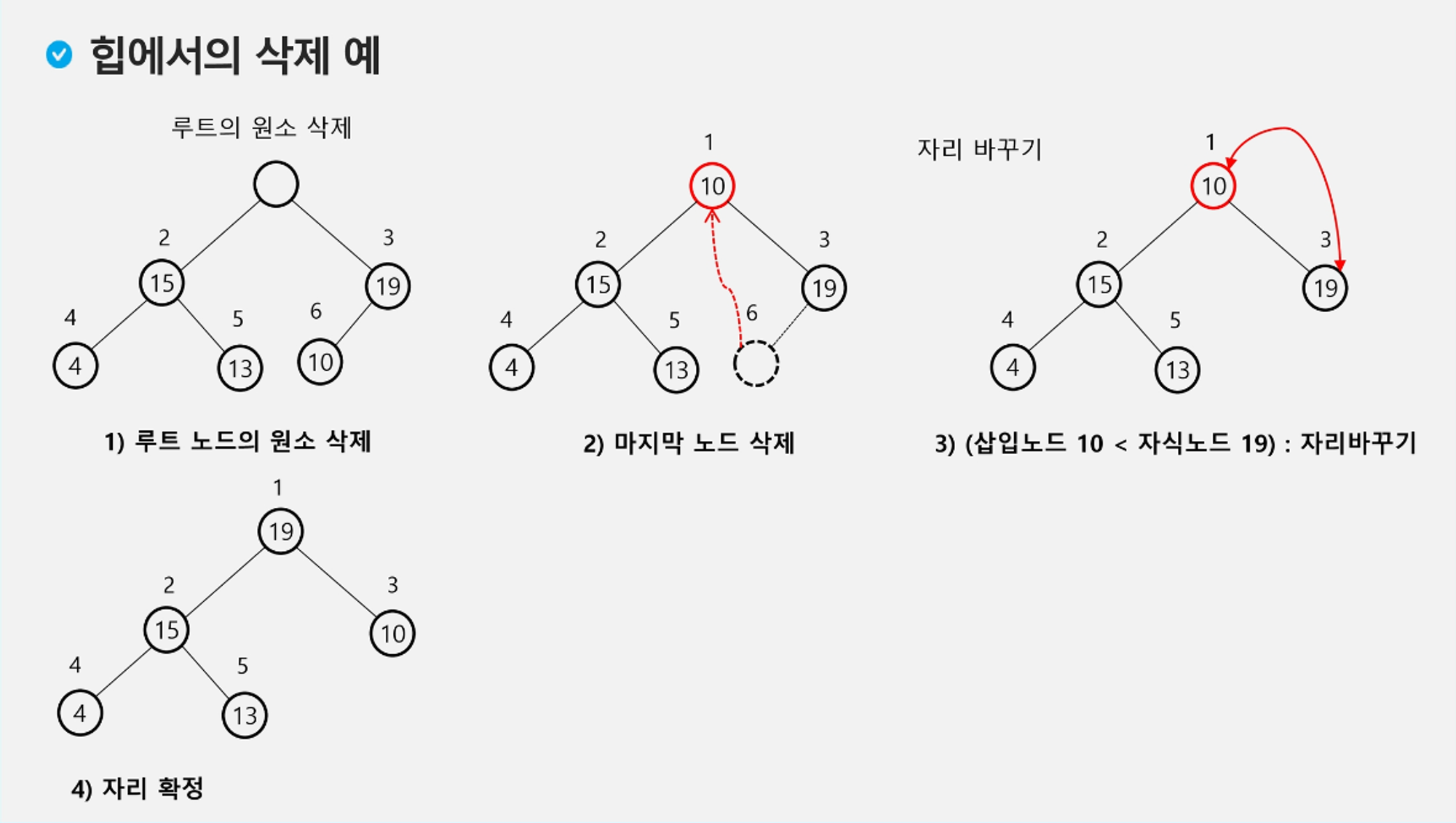
예제
def enq(node): global last last += 1 # heap[last] = node child = last parent = child // 2 # 완전탐색이니까 가능 while parent and heap[parent] > heap[child]: # 부모가 있고, heap[parent], heap[child] = heap[child] , heap[parent] child = parent parent = child // 2
def deq(): global last tmp = heap[1] heap[1] = heap[last] last -= 1 # top 쓰듯이 p = 1 c = p * 2 # 대표자식이 왼쪽으로 가정 while c <= last: # 왼쪽 자식이 있으면 if c + 1 <= last and heap[c] > heap[c+1]: # 오른쪽 자식이 있고, 오른쪽이 더 작으면 선택 (최소힙) c += 1 # 부모 > 자식 일 때 교체 if heap[p] > heap[c]: heap[p] , heap[c] = heap[c], heap[p] p = c c = p * 2 else: break return tmp
arr = [7,2,5,3,4,6]
n = len(arr)
heap = [0]* (n+1) # 완전 이진 트리
last = 0 # 노드가 하나도 없는 상태
for i in range(n): enq(arr[i])
print(heap)
for i in range(n): print(deq())heapq 라이브러리
사용 예제
import heapq
# 최소힙만 지원한다.
heap = [7,2,5,3,4,6]
heapq.heapify(heap)
print(heap)
heapq.heappush(heap,1) # 어떤 배열에 무엇을 넣을 것인지
print(heap)
while heap: print(heapq.heappop(heap), end=' ')
print()
# 최대합
temp = [7,2,5,3,4,6]
heap2 = []
for item in temp: heapq.heappush(heap2, -item)
print(heap2) # 음수지만, 큰 순서로 보인다
heapq.heappush(heap2,-1)
print(heap2)
while heap2: print(heapq.heappop(heap2) * -1)인덱스를 이용해서 모양을 저장 → 부모-자식 간 관계를 알 수 있다면 1차원 배열로 저장가능
노드번호 //2 → 부모
번호 x2 → 왼쪽
번호 x2 +1 → 오른쪽
이럴 경우 배열로서 저장가능

